会社からClaude Enterpriseのアカウントを支給されていて、理論上は十分足りるはずでした。ところが業界レポートや製品資料をまとめて分析しようとすると、PDFなどをどさっと放り込むだけで、午前中のうちにその日の割り当ての大半を使い切ってしまうことがよくありました。費用そのものは問題ではありません。落ち着かないのは、「まだ作業が終わっていないのに、もう上限が見えてきた」という切迫感でした。これがきっかけで、あることを考えるようになりました。AIによる情報処理はトークン単位で課金される――では、ファイル形式が違うと、送り込まれる「文字数」は本当に同じなのだろうか、ということです。
入力形式の影響は、思っていた以上に大きい
直感的には、同じ内容なら形式を変えてもさほど差はないだろうと思っていました。しかし実際は違います。
大規模言語モデルは文字列をトークンに分割して処理します。Markdownは記法のオーバーヘッドが極めて小さく、3段見出しを表すのに # を3つ書くだけで済みます。一方HTMLでは <h3></h3> のようなタグが必要になり、Word文書(.docx)に至っては、その正体はZIP圧縮されたXMLの集合体で、フォントサイズ、色、書体、余白といった、人間の目には意味があってもモデルには不要な視覚メタデータが大量に混在しています。
以下はおおよその消費量の目安です(厳密な測定値ではなく、内容の構造によって実際には差が出ます)。
| 形式 | 相対トークン消費量(Markdown = 100) |
|---|---|
| Markdown(.md) | 100(基準) |
| プレーンテキスト(.txt) | 95〜100 |
| HTML(.html) | 140〜200+ |
| Word(.docx) | 250〜400+ |
| PowerPoint(.pptx) | 350〜600+ |
| PDF(.pdf) | 200〜800+(解析精度による) |
| 画像(JPG/PNG、1080P) | 約1,100(ピクセルグリッド換算) |
画像については特に説明が必要です。モデルは画像のピクセルを「文字として読む」わけではなく、一定サイズのグリッドに分割してブロックごとに処理します。1080Pの画像1枚が消費するトークンは、同等の情報量を持つMarkdownテキストの10倍以上にもなります。契約書のスキャン画像や梱包リスト、請求書のように本質的には文字情報であるものは、先にOCRをかけてMarkdownに変換してから読み込ませるのが最も効率的です。
AIにも聞いて、判断を裏付ける
推測だけでは心もとなかったので、別途契約しているGeminiにも同じ質問を投げてみました。異なるファイル形式をモデルに入力した場合、トークン消費量にどれほどの差が出るのか、という問いです。
結果は自分の予想とおおむね一致していました。プレーンテキスト系の用途ではMarkdownが最も節約的な形式であり、PDFやOffice系形式は構造情報やスタイル情報を大量に抱え込んでいるため、消費量が顕著に増える傾向にあるとのことでした。最も理想的な手順は、内容をモデルに渡す前に一度「削ぎ落として」、Markdownに変換しておくことです。これに気づいてから、日々の分析コストの相当部分が、ファイル形式が抱える「ノイズ」に食われていたのだと実感しました。
使いやすいツールを探す:ウェブページをきれいなMarkdownに
方向性は見えたので、次はツール探しです。
マイクロソフトが公開しているオープンソースのMarkItDownというPythonライブラリは、各種ファイルをMarkdownに変換することに特化していて、PDF、Word、Excel、PowerPointなどに対応し、変換品質もかなり良好です。ただしコマンドライン専用のツールで、使うたびにターミナルを開く必要があり、日常的に頻繁に使うには不向きでした。
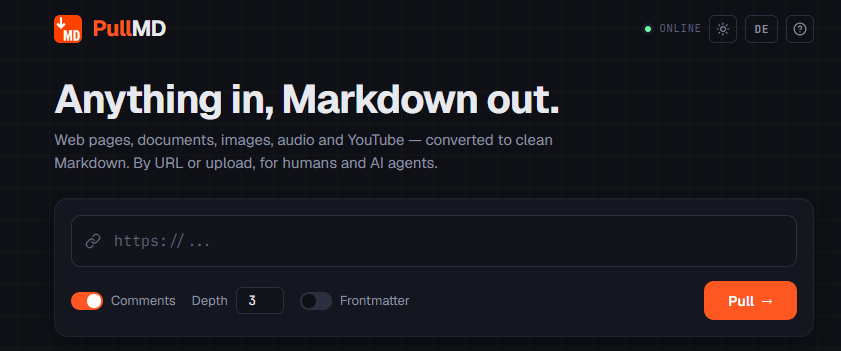
GitHubをひととおり探した結果、pullmd(AeternaLabsHQ/pullmd)というプロジェクトに行き着きました。これはセルフホスト型の「ウェブページURL→Markdown変換サービス」で、最新のv3ではマイクロサービス構成が採用されています。静的ページの本文抽出を担うTrafilatura、JavaScriptレンダリングが必要な動的ページに対応するPlaywright、そしてOffice/PDF文書の変換を補うサイドカーとしてのMarkItDownが統合されており、コメントツリーを含むReddit投稿の取得にも対応しています。変換結果はPWA画面上にそのまま表示され、ワンクリックでコピーできます。
これで、ウェブページとOffice/PDF文書という2種類のニーズが1つのサービスでまかなえるようになりました。日々AIに読み込ませる内容のうち、業界ニュースや調査レポートのウェブページ、取引先のサイト、契約書の添付ファイルはかなりの割合を占めています。
Easypanelでのデプロイ記録
pullmd v3はメインサービス1つと、3つのサイドカー(Trafilatura、Playwright、MarkItDown)で構成されています。もっとも手間のかからないデプロイ方法は、EasypanelのCompose機能を使って、Docker Composeの設定を直接インポートすることです。
まずハードウェア要件を確認
PlaywrightのイメージにはChromium、Firefox、WebKitの3つのブラウザエンジンが含まれており、サイズは約3.7GBあります。サーバー側には以下を確保しておくことをお勧めします。
- 空きディスク容量 5GB以上
- 空きメモリ 2GB以上
ステップ1:Composeを作成する
Easypanelの管理画面にログインし、Create Projectをクリックして、名前を pullmd とします。プロジェクトに入ったらGo to Projectをクリックし、右上のCreate → Compose(Docker Composeによる作成)を選びます。
ステップ2:Docker Composeの設定
以下の設定をComposeの編集ボックスに貼り付けます。この設定は実際のデプロイ中に出た警告を踏まえて整理済みで、廃止された version フィールドと、Easypanelの命名機構と衝突する container_name を取り除いてあります。
services:
pullmd:
image: aeternalabshq/pullmd:latest
restart: unless-stopped
environment:
- PUBLIC_URL=https://${APP_DOMAIN}
- TRAFILATURA_URL=http://trafilatura:8001/extract
- PLAYWRIGHT_URL=http://playwright:8002/render
- MARKITDOWN_URL=http://markitdown:8003/convert
- CACHE_DB=/data/cache.db
volumes:
- data:/data
depends_on:
- trafilatura
- playwright
- markitdown
trafilatura:
image: aeternalabshq/pullmd-trafilatura:latest
restart: unless-stopped
playwright:
image: aeternalabshq/pullmd-playwright:latest
restart: unless-stopped
markitdown:
image: aeternalabshq/pullmd-markitdown:latest
restart: unless-stopped
volumes:
data:
補足しておきたい点がいくつかあります。
version:とcontainer_name:は追加しない――現行のDocker Compose仕様では冒頭のversion宣言はもはや不要です。container_nameを指定すると、Easypanel独自のコンテナ命名機構と衝突する可能性があります。Easypanelは自動的に規約に沿った名前をコンテナに割り当ててくれます。${APP_DOMAIN}変数について――これはEasypanelの動的変数で、まだドメインを紐付けていない段階では「variable is not set」という警告が表示されますが、イメージの取得やサービスの起動には影響しません。ステップ3でドメインを紐付ければ、次回のデプロイ時にこの警告は自動的に消えます。
ステップ3:ドメインを紐付ける
pullmdのメインサービスに入り、Domainsタブ →Add Domainで、用意しておいたドメイン(例:pullmd.yourdomain.com)を入力し、Portには 3000(pullmdの内部デフォルトの待ち受けポート)を入力して保存します。
紐付けが完了すると、Easypanelは自動的にドメインをComposeファイルの ${APP_DOMAIN} 変数に注入します。ドメインの浸透を待たずにIP+ポートだけでとりあえずアクセスしたい場合は、環境変数の PUBLIC_URL を実際のアドレスやサーバーIPに直接書き込んでも、同様に問題なく動作します。
ステップ4:デプロイ
Composeのメイン画面に戻り、Deployをクリックします。4つのイメージが順に取得され、Playwrightのサイズが大きいため初回は3〜5分ほどかかります。すべてのステータスが緑色のRunningになれば完了です。
デプロイ中にcontainer_name、version、APP_DOMAINに関する黄色い警告が出ても、慌てる必要はありません。いずれも注意喚起にすぎず、デプロイの失敗にはつながりません。上記で整理した設定に従えば最初の2つの警告はそもそも出なくなり、3つ目もドメインを紐付ければ自然に解消します。
オプション:画像解析と音声文字起こしを有効にする
pullmd v3の画像説明機能(Vision)や音声文字起こし機能(STT)を使いたい場合は、pullmdメインサービスのEnvironmentタブに、それぞれのAPIキー、Base URL、モデル名のパラメータを追加すればよいです。両機能ともOpenAI互換のインターフェースを利用しているため、必要に応じて設定すれば、基本のウェブページ→Markdown変換機能には影響を与えません。
実際に使ってみた感想
デプロイが完了すると、紐付けたドメインからアクセスするだけでシンプルなPWA画面が開きます。ウェブページのリンクを貼り付ければ、数秒できれいなMarkdownが生成され、そのままコピーしてClaudeに分析させることができます。ナビゲーションバーや広告、フッターといった無関係なノイズがもう混じることはありません。
これまでのように元のウェブページのリンクやHTMLをそのまま投げていた場合と比べると、同じ内容に対するトークン消費が明らかに減りました。それ以上に大きいのは、変換後のテキスト構造がすっきりすることで、モデルの回答の質もあわせて上がったことです。入力のノイズが減れば、出力の精度も自然と上がります。
ツール自体は決して複雑なものではありませんが、日々の作業フローに組み込んでからは、「気づいたら割り当てを使い切っていた」という感覚はかなり減りました。
pullmdのプロジェクトページ:github.com/AeternaLabsHQ/pullmd
.png)

